ggplot 쉽게 배우기 (2) - 히스토그램
지난 기초 강의(1) 에 이어 ggplot의 주요 그래프에 대해 알아보겠습니다.
다시 한번 [데이터 + 배치 + 표현]을 기억하시고.
library(tidyverse)
기본 세팅 후 시작합니다.
연속? 분리?
지난 시간에는 ggplot을 통한 시각화 중, 가장 많이 사용하는 산점도(Scatter Plot)를 그려봤습니다.
[데이터+배치] + "점(표현)" 이라고 생각할 수도 있겠군요.
다른 표현 방식에는 어떤 것이 있을까요?
대부분의 사람들은 데이터 과학이나 연구를 해본 적이 없기에 이런 질문에 대답하기 어렵습니다.
(그래서 시각화 초보의 경우 자동 추천 기능이 있는 Tableau를 사용하는 것도 나쁘지 않습니다)
문제를 간단히 하기 위해 데이터를 두 가지로 설정하겠습니다.
- 1,2,3,4... 와 같이 분명히 나뉘지 않고 이어지는 경우(continuous)
- "파란색, 빨간색"과 같이 분명히 나눠지는 경우(discrete/nomial)
문제가 조금 단순해졌군요.
이제 자주 쓰이는 시각화를 중심으로 ggplot 실습을 시작하겠습니다.
히스토그램(Histogram)
앞서 그려본 산점도(scatter plot)의 경우 두 값 사이의 관계(Correlation) 를 보기 위해 x축, y축을 사용합니다.
그렇다면, 하나의 값이 대략 어떻게 생겼는지 확인하려면 어떤 시각화를 쓰면 될까요?
(좀 더 어려운 표현으로 데이터의 분포(Distribution)를 확인하다고 합니다)
구체적으로 "1,2,3과 같이 연속되는 숫자로 이뤄진 데이터 중 어떤 범위가 많고 적은지 확인하려면?" 어떻게 할까요?
이 경우, 학교에서도 배우는 유명한 시각화 방식 중 하나인 히스토그램을 사용합니다.
기본 데이터셋인 mpg 데이터셋 중 배기량(displ)의 분포를 확인해 봅시다.
데이터 : mpg
배치 : displ (변수가 하나로 자동배치됩니다)
표현 : histogram
ggplot(data=mpg, mapping = aes(displ)) + geom_histogram() # 에러 발생 후 시각화
# `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
에러 메시지가 나오면서 시각화가 이뤄집니다.
왜 에러 메시지가 나올까요? 우리가 얼마나 데이터를 잘라놓을지 설정하지 않았기 때문입니다.
(이 경우, 메시지 내용처럼 기본값을 사용합니다)
이제, 기본값 30보다 더 작은 단위(10개 블록)로 분할해서 시각화를 수행해 봅시다.
데이터 : mpg
배치 : displ (변수가 하나로 자동배치됩니다)
표현 : histogram (10 블록으로 잘라서)
ggplot(data=mpg, mapping = aes(displ)) + geom_histogram(bins=10)
# "bins = 값"에 따라 분할 정도가 달라집니다.

더 넓은 단위로 데이터 범위가 설정된 것이 확인됩니다.
그렇다면, 생각을 반대로 해서 "일정한 단위로 잘라야 할 때" 어떻게 설정하면 좋을까요?
이 때는 간단하게 binwidth라는 값을 설정하면 됩니다.
데이터 : mpg
배치 : displ (변수가 하나로 자동배치됩니다)
표현 : histogram (0.1 단위로 범위를 설정해서)
ggplot(data=mpg, mapping = aes(displ)) + geom_histogram(binwidth=0.1)
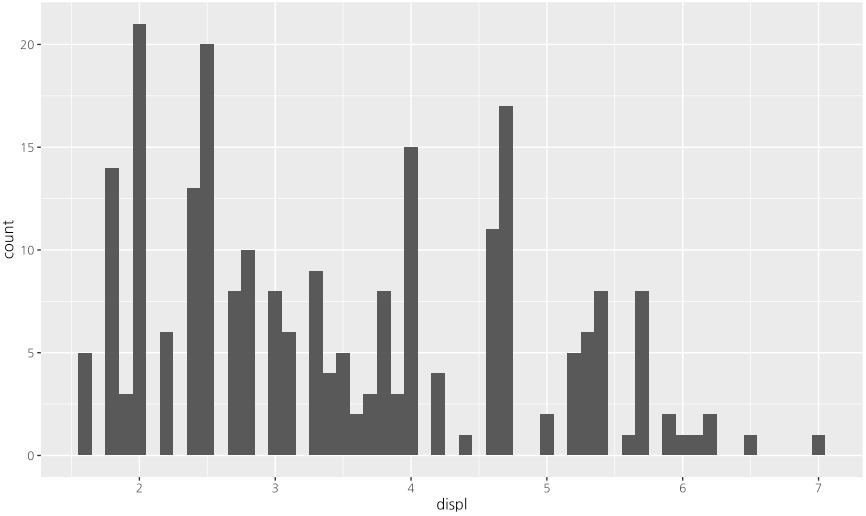
색 설정하기
사실, 이 정도로도 보고서에 쓰기에는 충분하지만 여러가지 아쉬운 점이 많습니다.
디테일 문제를 해결하기 위한 추가 패키지가 존재하지만 이것은 나중에 배우기로 하고
ggplot 자체적으로 지원하는 기능을 알아보겠습니다.
우선, ?를 활용해서 함수설명을 확인해 봅시다.
?geom_histogram
많은 옵션이 나오지만, 실제로 제가 가장 많이 질문을 받은 내용은 "색"과 관련된 내용입니다.
구체적으로 색 설정과 관련해서는 3개의 옵션을 많이 사용합니다.
1) 테두리 색(color)
2) 내부 색(fill)
3) 투명도(alpha)
여기서 색을 설정하는 방식에는 두 가지가 존재하는데 1) 색이름(black, blue)을 쓰거나 2) 색 코드를 사용하는 방식이 존재합니다.
(저같이 디테일에 집착하는 사람은 2번을 선택합니다...)
말로 들으면 이해하기 어려우니 모든 내용을 넣어 하나씩 설정해 보자면
ggplot(data=mpg, mapping = aes(displ)) + geom_histogram(bins=10, fill="#f58442")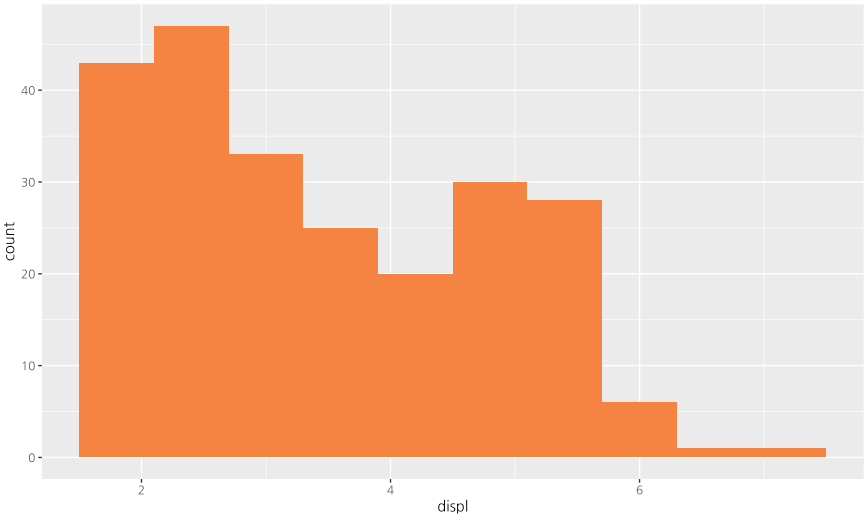
ggplot(data=mpg, mapping = aes(displ)) + geom_histogram(bins=10, fill="#f58442",alpha=0.5)
ggplot(data=mpg, mapping = aes(displ)) + geom_histogram(bins=10, color = "black", fill="#f58442",alpha=0.5)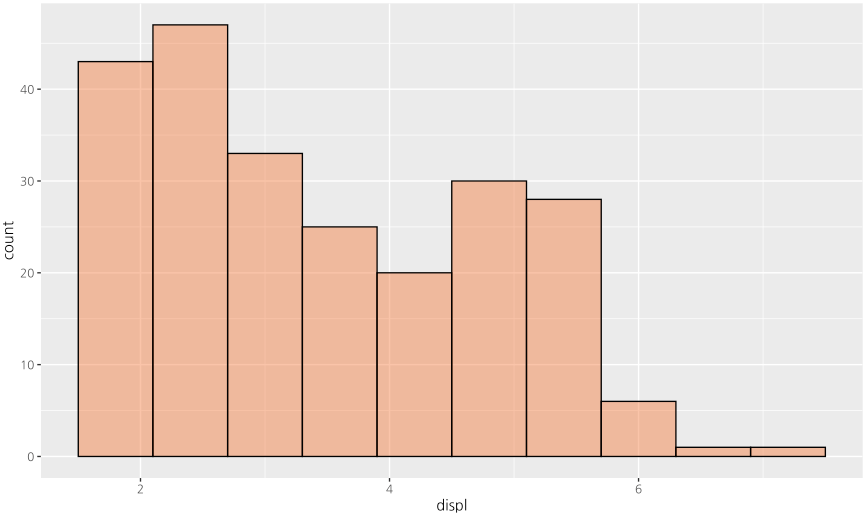
이와 같은 차이점이 존재합니다.
다 좋지만, 코드가 길어져서 가독성이 떨어지니 약간 보완할 필요가 있어 보입니다.
이전에 배운 코드 간략화를 활용한다면 다음과 같이 정리할 수도 있겠군요.
base <- ggplot(data=mpg, mapping = aes(displ))
base + geom_histogram(bins=10, fill="#f58442")
base + geom_histogram(bins=10, fill="#f58442", alpha=0.5)
base + geom_histogram(bins=10, color = "black", fill="#f58442", alpha=0.5)
정리
이번 시간에는 이전에 배운 기본 구조에 더해, 세부 옵션을 통해 히스토그램을 그리고 디테일을 수정해 봤습니다.
히스토그램은 연속된 데이터의 전반적인 모습(분포)를 확인하기 유용한 시각화입니다.
다만, bin 혹은 binwidth를 설정하는 과정에서 복잡한 면이 존재합니다.
그렇다면, 이를 해결할 다른 방법이 존재할까요? 다음 포스팅에서 다뤄보도록 하겠습니다.