<차이>가 아닌 <상관관계>를 보자
지금까지 우리는 A그룹 B그룹의 차이(t-test) 혹은 분포의 유사성이나 상관관계(Chi-Square)에 대해 공부했습니다.
하지만, 통계 검정에는 단순히 두 그룹의 차이만 확인하는 기법만 있지 않습니다.
오늘 배울 상관관계 분석(Correlation analysis)은 두 그룹의 "차이"가 아닌 "상관관계"에 집중하는 분석 방식입니다.
특히, 상관관계 분석은 나중에 배울 회귀분석(Regression)과 연결된다는 점에서 한번 정도 확인하고 넘어갈 필요가 있습니다.
상관관계 분석(Correlation analysis)의 종류
막연하게 두 변수의 상관관계를 알아보겠다고 했지만, 사실 상관관계를 측정하는 방식에는 여러 방식이 있을 수 있습니다.
1) 데이터의 유형에 따라 범주형과 연속형의 차이가 있을 수 있고
2) 상관관계 정도를 표현하는데 있어 +부터 -까지의 범위와
3) 상관관계의 수준에 따라 범위의 차이가 존재할 수 있습니다
그런 이유로 상관관계 분석은 여러 분파(?)가 존재하는데, 이 중 가장 많이 언급되는 것은 오늘 배울 피어슨의 방식입니다.
피어슨의 상관계수(correlation coefficient) = 피어슨의 r(Pearson's r)
피어슨의 r(상관계수)는 두 변수가 모두 연속된 값일 때 적용하는 방식입니다.
다음과 같은 연구 문제가 상관계수 분석에 적합한 의문입니다.
- 학교와의 거리가 멀수록 성적이 낮아질까?
- 소득수준이 높을수록 비만율이 낮을까?
- 인터넷 사용량이 높을수록 행복도는 떨어질까
여기서 중요한 것은 1,2,3,4와 같은 형태를 갖고 있더라도 "순위/등급"은 피어슨의 상관계수를 적용하기 적합하지 않다는 점입니다.
이는 다음 시간에 배울 스피어먼의 로Rho와 깊은 관계가 있습니다.
또 하나의 중요한 점은 무조건 상관관계가 "높다 vs 낮다"가 아닌 0을 기준으로 1이 최댓값 -1이 최솟값을 갖는다는 점입니다.
이렇게 하지 않으면 단위에 따라 상관관계가 왜곡될 수 있으니까요.
- 참고로, 데이터 과학자들은 -1~1로 변환하는 트릭을 표준화(Normalization)이라고 부릅니다.
실습 준비
실습에는 이전 통계 분석 과정과 같이 pingouin, pandas, seaborn 패키지를 사용합니다.
설치는 다음 포스팅을 참조해 주세요.
2022.07.31 - [데이터과학 기초/Python배우기] - conda로 손쉽게 파이썬 환경 관리하자 (Intel부터 M1까지) - 기초
실습 환경은 Jupyter 에서 실행됐습니다.
데이터셋/탐색
이번에 활용한 (가상) 데이터셋은 마케팅(광고) 빈도와 판매량의 관계입니다.
제시된 sales.csv 파일을 다운로드하여 파이썬 폴더에 넣어주세요.
import pandas as pd
sales = pd.read_csv("sales.csv")
sales.head()
데이터 프레임에 head 명령어를 사용하여 간단하게 데이터셋이 로드된 것을 확인했습니다.
이제 데이터의 전반적인 형태를 알아보기 위해 탐색을 수행합니다.
sales.decribe()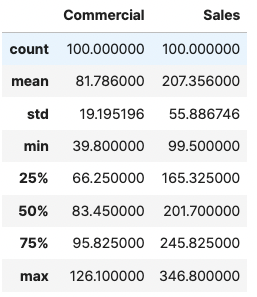
광고(commercial)와 판매량(sales) 각각에 대해 평균, 표준편차, 최댓값과 최솟값을 구했습니다.
이제 시각화를 통해서 구체적인 데이터의 형태를 파악해 보겠습니다.
데이터 분포 시각화와 산포도(Scatter Plot)
지금까지 t-test에서 수행했던 여러 테스트에 더해 상관관계의 시각화에는 두 변수의 "관계"를 확인하기 위한 시각화가 추가로 요구됩니다.
보통 이를 위해서 "산포도(Scatter Plot)"를 사용하는데요, 간단히 말해 x축 y축에 각각의 점을 배치하는 것입니다.
특히, 산포도의 경우 앞으로 배울 회귀분석(Regression) 등 데이터 과학 전반에서 사용되는 형태기 때문에 명령어를 외워놓는 편을 추천합니다.
말로 표현하면 복잡하지만, 실제로 시각화 해 보면 바로 이해할 수 있습니다.
import seaborn as sns
sns.scatterplot(data=sales, x="Commercial", y="Sales")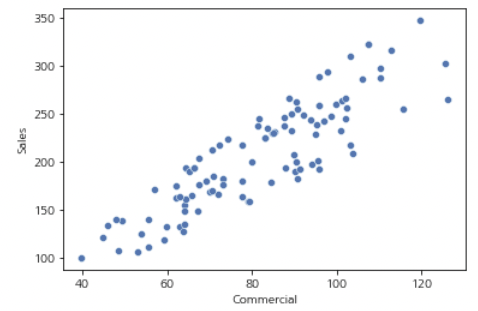
아마 논문이나 보고서를 자주 본다면 매우 익숙한 형태일 겁니다.
우리가 한눈에 보기에도 광고와 판매량 사이에는 특정한 상관관계가 존재하는 것 처럼 보입니다.
이제, 이런 관계가 통계적으로 유의한 수준인지 검정해 보도록 하겠습니다.
통계 분석과 정규성 검정
이전에도 언급한 바 있지만, 통계 분석 결과가 제대로 제시되기 위해서는 각 기법에서 요구하는 조건을 만족하는지 확인할 필요가 있습니다.
피어슨의 r의 경우, 통계 검정의 조건은 1) 각 변수가 연속형이고 2) 정규분포를 가질 것 이라는 것입니다.
연속형의 경우는 시각화에서 이미 확인했으니, 두번째의 정규분포를 확인해 보면 되겠군요.
이전에도 다룬 내용이지만, 처음 보거나 기억이 나지 않는 분들을 위해 아래 게시물을 준비했습니다.
2022.08.02 - [데이터과학 기초/통계] - 파이썬으로 단일표본 t-test 돌리기
우리는 두 변수가 정규분포인지 확인하려 하기 때문에, 샤피로-윌크 검정을 사용하면 됩니다.
import pingouin as pg
pg.normality(sales.Commercial)
정규성(Normality) 조건을 만족하는군요(정규성 검정의 경우 다른 통계의 검정과 달리 p-value가 0.05 이상이어야 조건을 만족합니다).
똑같이, Sales 변수에도 같은 방법을 적용해 보겠습니다.
import pingouin as pg
pg.normality(sales.Sales)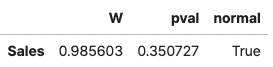
두 변수 모두 조건을 만족했기 때문에, 상관관계 분석을 수행할 수 있습니다.
통계 검정
통계 기법 적용을 위한 조건을 모두 만족했기 때문에 상관관계 분석을 수행할 수 있습니다.
계산 결과를 편하게 보기 위해, 소수점 자리를 제한하여(round 명령어) 통계 검정 결과를 확인하겠습니다.
import pingouin as pg
pg.corr(sales.Commercial, sales.Sales).round(3)
검정 결과에 따르면, p-value가 0.05보다 작기 때문에 귀무가설을 기각하고 대립 가설(서로 상관관계가 존재)을 채택합니다.
또한, 상관관계의 강도는 0.876으로 꽤 높은 수준임을 알 수 있습니다.
(단, 어디까지나 주관적 판단이기 때문에, 보고서에 꽤 높은 수준이라고 보고하면 안됩니다)
상관관계 분석 결과 보고
꾸준히 통계 포스팅에서 제시한 바 처럼 통계 보고서에는 세 가지 요소를 넣어주시면 됩니다.
1. 어떤 기법을 사용했는가?
피어슨의 r 혹은 피어슨의 상관관계.
2. 통계 결과
r = 0.876, p-value < 0.05 수준으로 유의하며 95%의 신뢰구간에서 [0.82, 0.91]
3. 결과 분석
광고량과 판매량 사이에 유의미한 상관관계가 존재하는 것이 확인됐다.
(주의할 점은 절대로 "인과관계"가 아니라는 점입니다. 이 부분은 나중에 설명하도록 하죠)
이 세 가지 내용을 조합하여 적어주시면 됩니다.
'데이터과학 기초 > 통계' 카테고리의 다른 글
| 파이썬으로 분산분석(ANOVA)하기 (1) - One Way (일원 분산분석) (0) | 2022.08.14 |
|---|---|
| 파이썬으로 상관관계(Correlation analysis) 분석하기 : 스피어만의 rho / 켄달의 tau (0) | 2022.08.12 |
| 파이썬으로 Chi-Square(카이 제곱)검정 돌리기 (0) | 2022.08.06 |
| 파이썬으로 대응표본 t-test 돌리기 (0) | 2022.08.04 |
| 파이썬으로 단일표본 t-test 돌리기 (0) | 2022.08.02 |



